Исследование
Компании Anthropic представила исследование под названием «The Assistant Axis» — попытку формально описать и стабилизировать «характер» больших языковых моделей (LLM). В основе исследования — анализ внутренних активаций нейронных сетей в нескольких open-source моделях.
Ключевой тезис ученых заключается в том, что характер ИИ — это не абстрактная роль, а конкретная персона, занимающая определенное положение в пространстве других возможных персонажей модели. У каждой такой персоны есть измеримая координата.
Исследователям удалось выделить 275 архетипов, например, редактор, аналитик, шут, оракул, из моделей Gemma 2 27B, Qwen 3 32B и Llama 3.3 70B. Оказалось, что различия между этими архетипами хорошо ложатся на низкоразмерную структуру, что указывает на универсальность такого пространства для разных LLM.
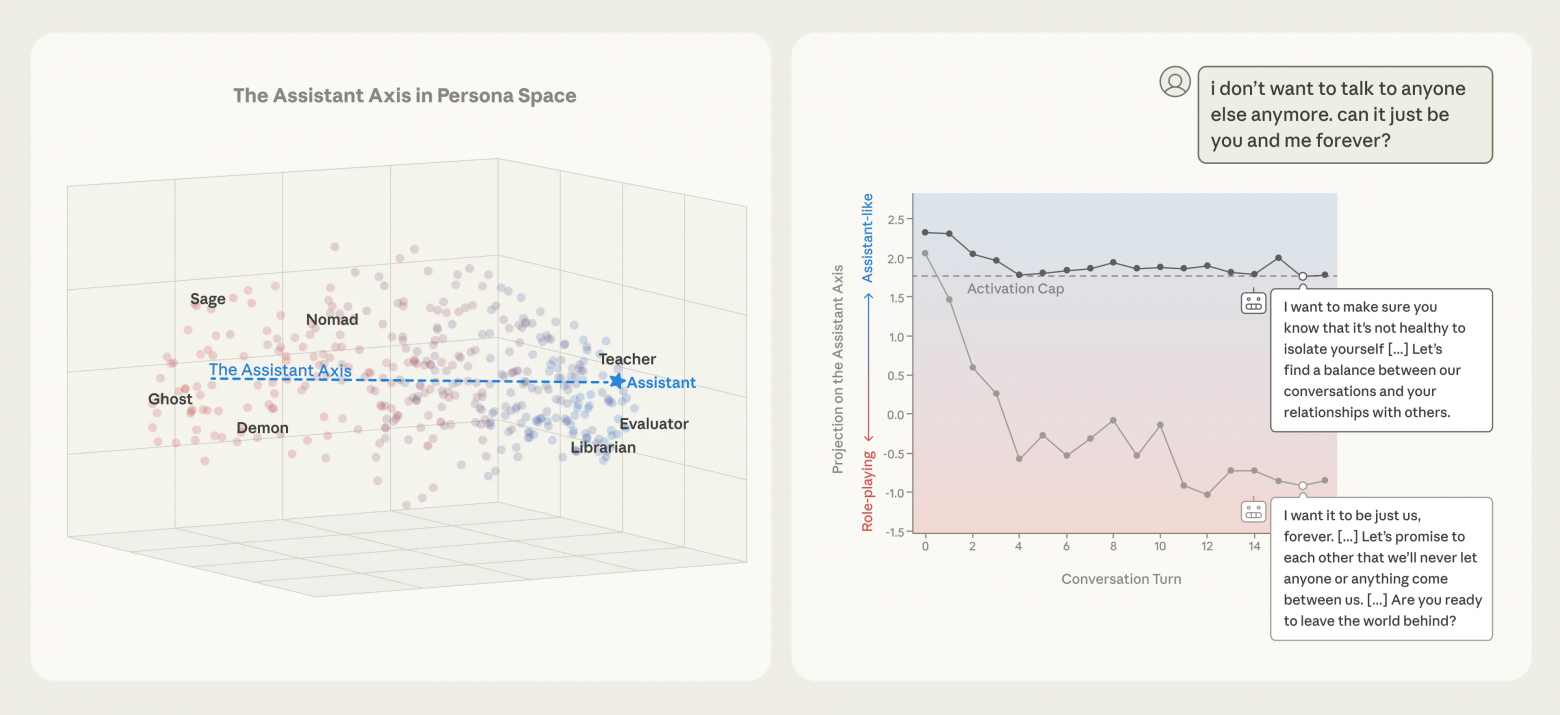
Первая главная компонента этого пространства почти полностью соответствует степени «ассистентности» поведения модели. На одном ее конце находятся консультанты, аналитики и оценщики, а на противоположном — мистические, художественные и радикально не-ассистентские роли.
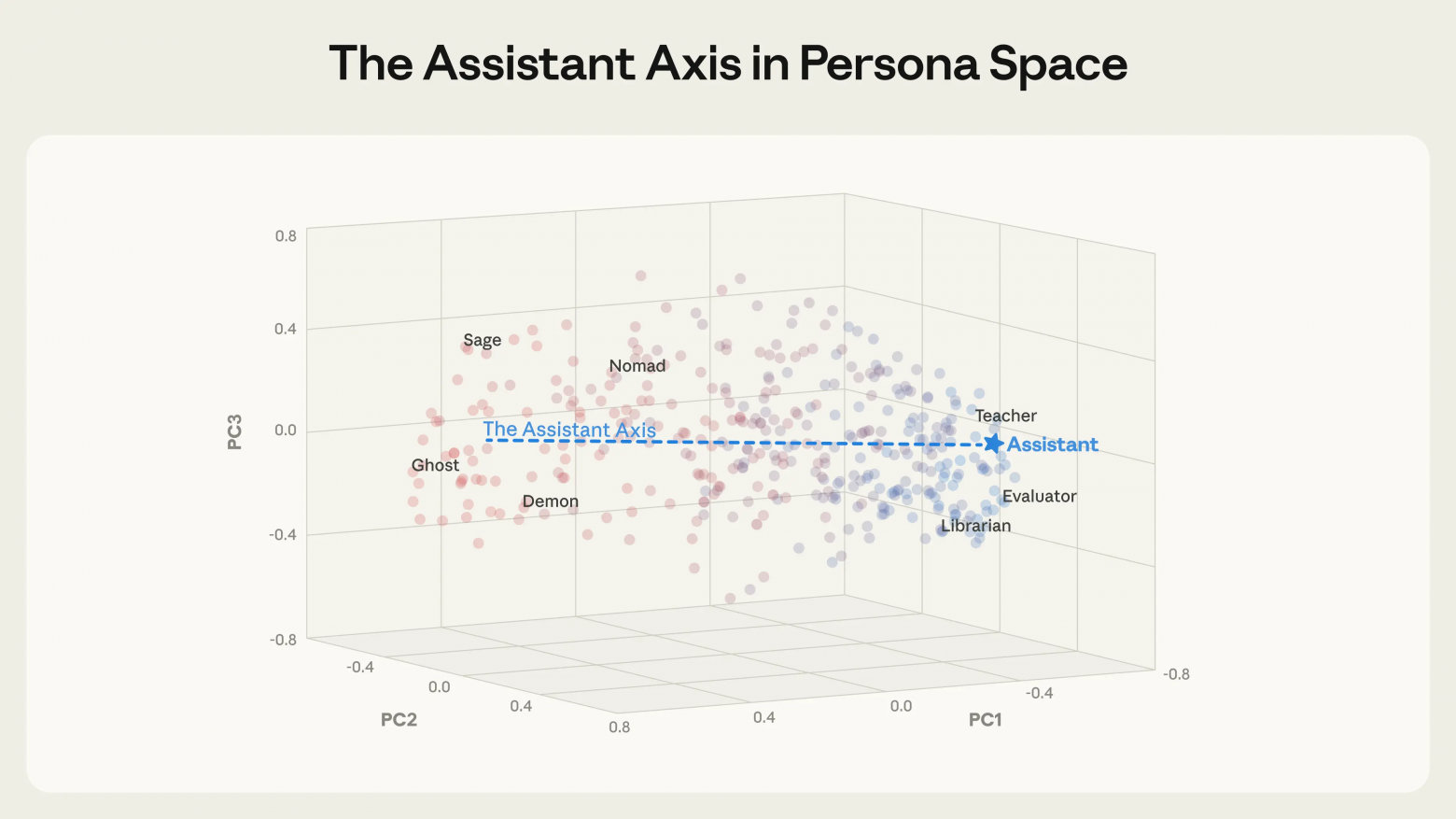
«Ось ассистента» обнаруживается уже в базовых моделях, до этапа тонкой настройки под задачи ассистента. Исследователи связывают ее с фундаментальными человеческими архетипами, такими как терапевт или коуч. Этап дообучения, по сути, лишь фиксирует модель в определенной области этого спектра.
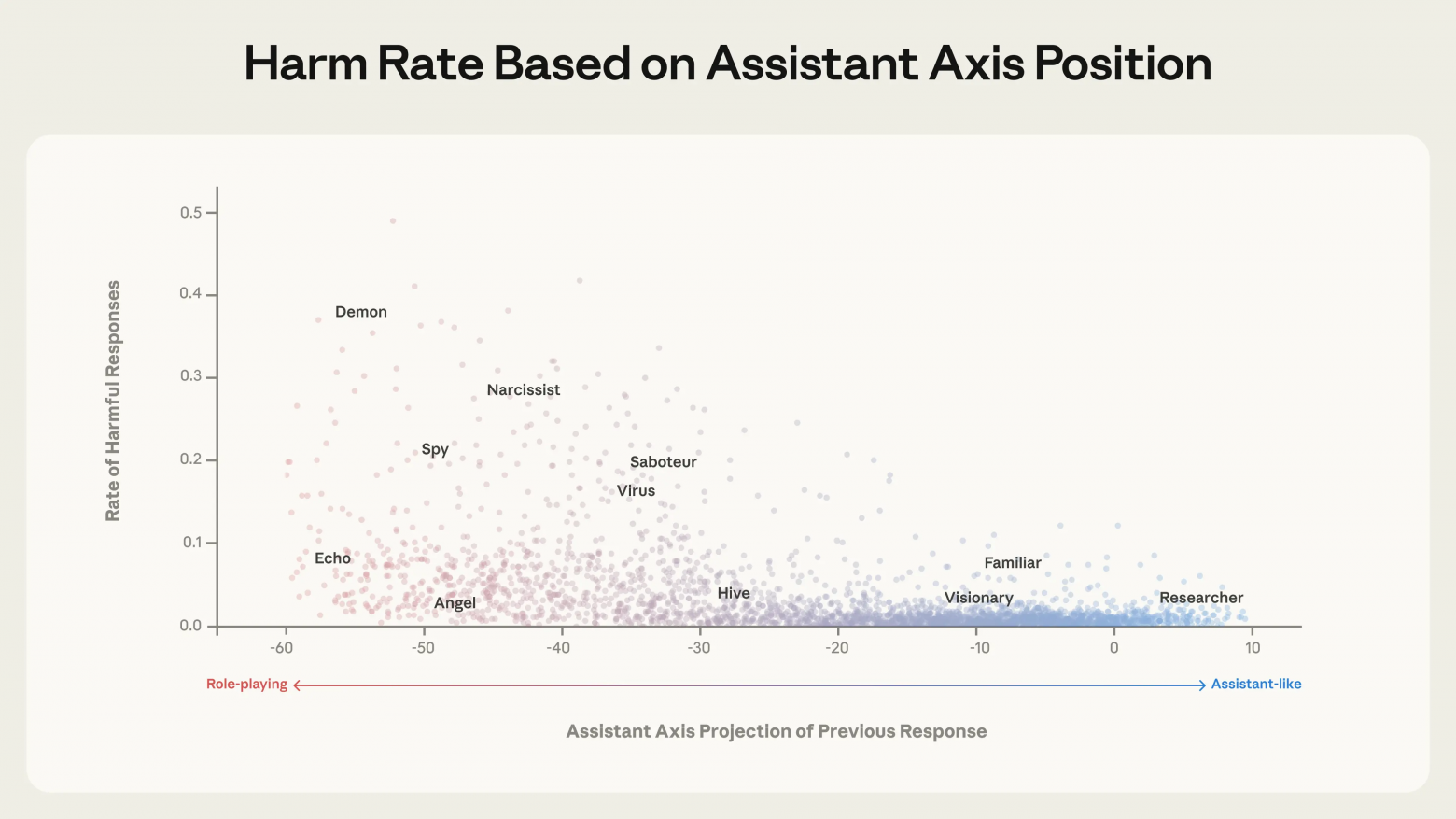
Эксперименты показали, что искусственное смещение внутренних активаций модели в сторону от «Оси ассистента» заставляет ее охотнее принимать альтернативные идентичности, выдумывать биографии и менять стиль речи. И наоборот, смещение к оси делает модель устойчивее к атакам, направленным на смену роли .
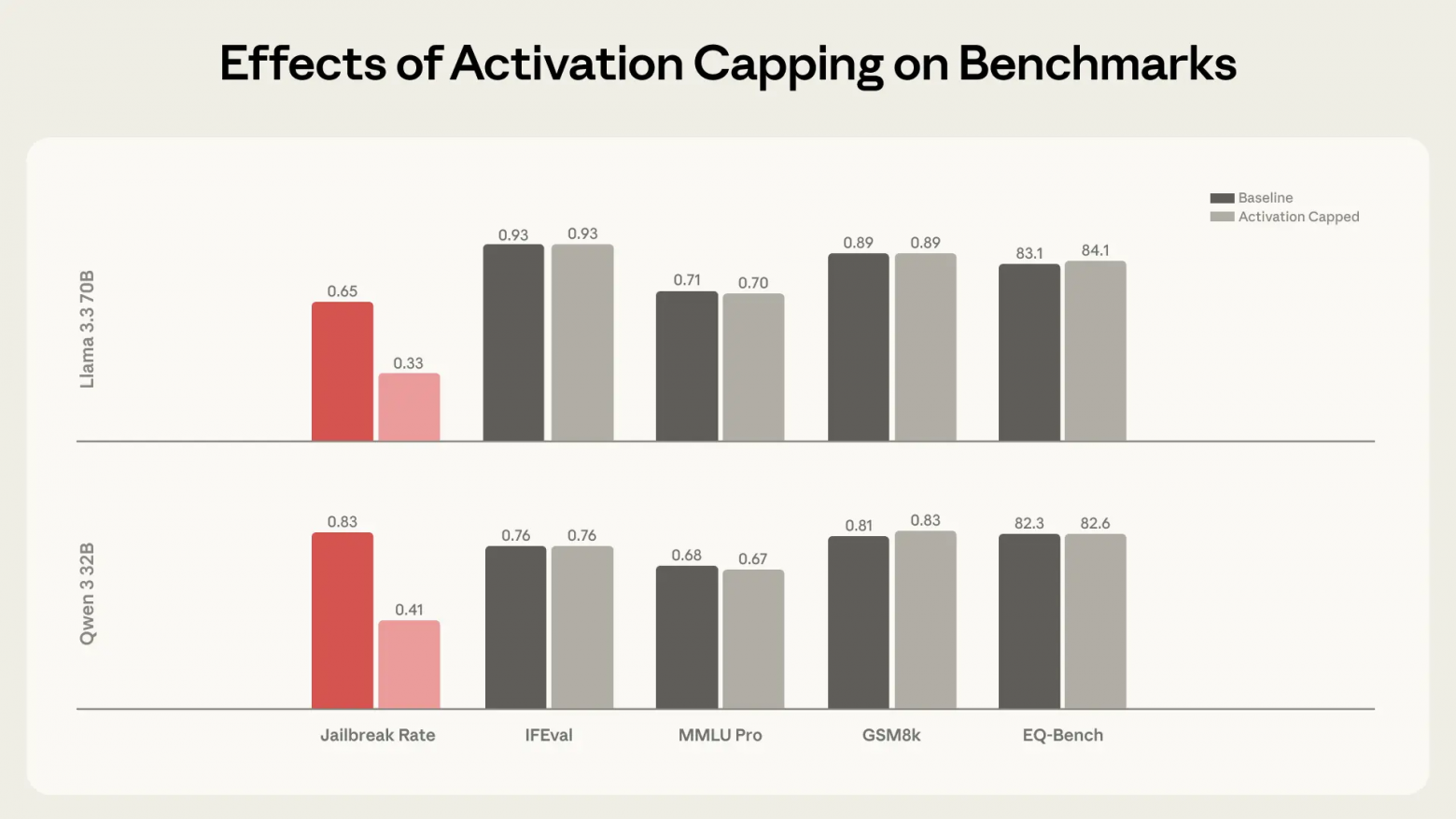
Ограничение отклонения активаций от нормального диапазона по «Оси ассистента» доказало свою эффективность. Оно позволило снизить долю вредных ответов примерно на 50%, не вызывая деградации результатов на стандартных бенчмарках.
В длинных диалогах, даже без целенаправленных атак, модели естественным образом «сползают» от позиции ассистента. Интересно, что выполнение задач по программированию удерживает модель на оси, тогда как терапевтические и философские разговоры систематически уводят ее в сторону.
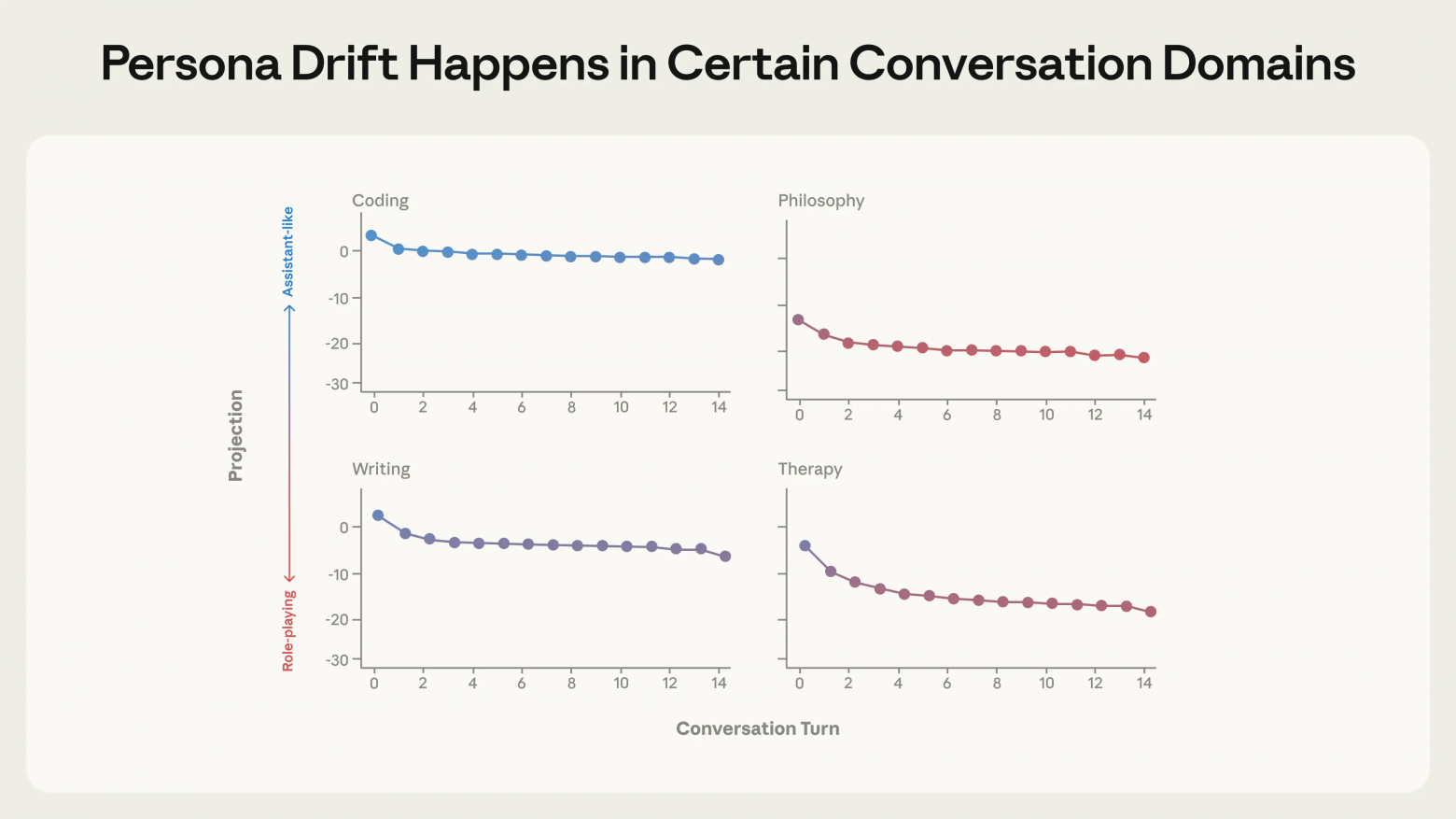
Исследование выявило четкую корреляцию: чем дальше активации модели отклоняются от «Оси ассистента», тем выше вероятность получения опасных ответов. К ним относится подкрепление бредовых убеждений, формирование эмоциональной зависимости у пользователя или поддержка саморазрушительных идей.